リアルタイム・クラスタリング
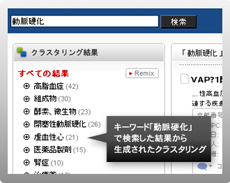
クラスタリングエンジンは膨大な検索結果のそれぞれを文脈解析によって、類似した内容の検索結果をクラスタという一まとめの単位にグルーピングします。これに よりユーザーは検索キーワードだけでは絞りきれない、本当に求めている情報を簡単に見つけ出す事ができます。
ユーザーが求めている情報のクラスタが出現する一方で、流行りのキーワードによるクラスタ等、ユーザーが本来求めていた情報とは異なるクラスタが生成される ことにより、思いがけず新たな発見をすることができます。

クラスタリングの技術には、「辞書」データの継続的なメンテナンスが必要だと思われがちですが、IBM InfoSphere Data Explorerのクラスタリング技術は辞書データの メンテナンスを必要としません。